星级打分
平均分:NAN 参与人数:0 我的评分:未评
本帖最后由 pasanonic 于 2022-12-20 18:07 编辑
买之前请您先过一遍,看看自己有没有耐心学习,能不能接受,如果想着那种傻瓜式的那请别浪费了您的石头,过个眼就好,还是需要一定的基础能力的.
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
只要是视频内的字幕,全部都可以提取
首先声明:我是经过原作者同意才转帖的,大家有什么需要交流需要改善的可以在压缩包内详细教程找到联系方式
本人赚个转运费 (有什么不懂的可以回帖,我把自己会的都告诉你)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
集成软件介绍:
本免费工具仅供个人使用,为业余提取字幕的朋友提供方便,不可用于商业目的,不可侵犯他人知识产权。 同时,本工具利用了OCR服务商的免费额度,作者建议有长期大量需求的用户,请购买OCR服务商的额度,支持国家高科技发展。
一、 目前为止可行的硬字幕(hardsub)提取方案1. 人工手提,用手和眼来提取时间轴和文字。 优点: 准确率高(废话)。 缺点: 费时费力,不能常做。
2. esrXP + IdxSubOcr(MODI OCR)esrXP提取视频中带字幕的图片(从而也就提取了时间轴信息),打包成idx+sub文件,然后导入IdxSubOcr用微软MODI ocr识别文字,生成一个srt字幕文件。 优点: 利用传统数字图像处理技术,获得字幕出现和消失的时间点,提取时间轴信息,准确率较高。 缺点: 老掉牙的微软MODI ocr识别引擎准确率较低,为了照顾MODI ocr,esrXP需要做较多设置、试验、调整参数的工作,以便提供漂亮的黑底白字clearTxT给MODI ocr,这就很考验用户的经验了。总体来说使用门槛高、识别率较低、工作量较大。虽然esrXP已经停更多时,但是苦于没有更好的选择,长期以来字幕爱好者只能将就着用。
3. VideoSubFinder + ABBYY FineReaderVideoSubFinde做类似esrXP的工作(不同的是单独保存每个字幕图片,不打包成idx+sub文件),ABBYY FineReader 15做类似IdxSubOcr的工作,将每个jpg字幕图片ocr识别为一个txt文件,然后回到VideoSubFinder 将所有txt文件合成一个srt文件。 优点: 跟esrXP类似,采用了更复杂的数字图像处理技术,提取视频中带字幕的图片和时间轴信息,更好提取算法,上手也更容易。ABBYY FineReader 15除了能ocr中英文,还支持其他语种。 缺点: VideoSubFinder仍然基于传统的数字图像处理技术(灰度膨胀腐蚀轮廓色度亮度相似度),虽然能较好提取普通静态字幕(显示固定颜色固定,大多数视频中硬字幕皆属此类),但是对于一些动态字幕(显示变化颜色不定),则难以提取。虽然暴露了很多参数给用户设置,但参数繁多难以理解,普通用户只能用默认设置。 ABBYY FineReader 15离线文字ocr引擎,虽然比MODI ocr好得多,但在实际使用效果上,还是不尽人意。
4. 硬字幕提取工具10(工具在文末下载)采用AI文字检测+传统的数字图像处理技术,提取字幕图片和时间轴信息(同时也集成了VideoSubFinder给习惯用户),然后利用百度讯飞有道OCR通用文字识别云引擎+离线ocr引擎识别出文字,在校对窗校对后生成srt字幕文件,最后还可选调用第三方工具APP(例如SubtitleEdit)做调轴补漏等工作,从开始到结束,整个字幕提取流程一气呵成,快速准确、识别率高、省时省力。 -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
教程:
一、 初次使用本软件总体来说,三个大步骤: 1、将字幕从视频中截图下来 2、将字幕图片OCR为文字 3、校对编辑字幕文件 具体步骤如下所述: 步骤1、准备百度OCR服务APP_ID / API_KEY / SECRET_KEY
 具体自行百度 步骤2、准备工作流程中最后可能用到的APP2第三方软件

步骤3、设置硬字幕提取工具打开工具,  点击‘系统设置’ 填入步骤1获得的百度OCR服务APP_ID / API_KEY / SECRET_KEY(如使用离线ocr引擎则不用做此步) 点Browse找到步骤2安装好的APP2的入口exe文件(如不需调轴补漏则不用做此步),然后Save保存设置(APP1已内置VideoSubFinder_5.50_x64不用填写)。 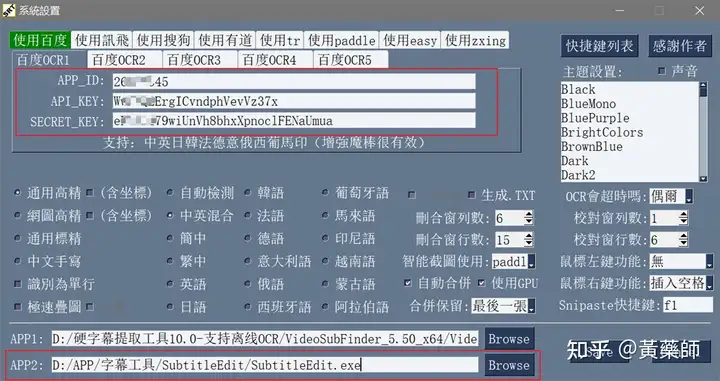
步骤4、用VideoSubFinder_5.50_x64生成RGBImages点击主界面VideoSubF按键,将启动运行VideoSubFinder_5.50_x64(旁边的‘智能截图’按键是类似于VideoSubFinder的另一个截图工具,采用AI文字检测+传统的数字图像处理技术,善于提取复杂动态字幕做得好可以100%不漏,高级用户可学习用户手册第四章之-高级功能)   点击左上角File -> Open Video(FFMPEG)(如不能打开视频,可换OPENCV),打开要提取字幕的视频文件(本例为:倚天屠龙记之魔教教主-中字.mp4) 快速浏览全片,查看字幕区间矩形最大范围(注意有些视频是两层字幕),用两根竖线两根横线设置字幕截图区间(四根线在视频窗口边缘不容易发现,试着点击选中可以移动它)。注意:矩形边框要比实际字幕稍大,不要为了节省图片尺寸而把区间设置成紧贴字幕,如果字幕周边余量太小,会影响后续百度OCR识别(当然也没必要设置得太大)。  点击Search右边的Settings,出现设置界面,我们只关心左边这块能影响Search字幕图片的参数。 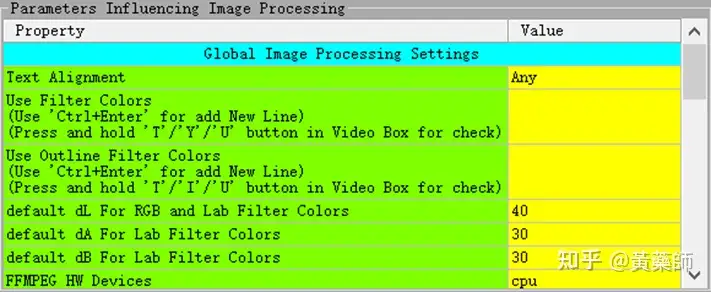 第一个参数‘Text Alignment’默认设置是‘Center’,须点击设置成‘Any’。 其他众多参数中,有一个参数至关重要,就是Use Filter Colors这项,default值是空的,其他参数可以不设,这个一定要设置上,特别是非纯白字幕,例如黄色!如果不设置,有大几率会漏字幕。 我们需要取色字幕文字的骨干颜色(骨干外则是字幕轮廓颜色,不要取偏了),然后将颜色值填入,将有助于VideoSubFinder判断字幕出现和结束的时间,生成正确的时间轴信息,并防止丢时间轴。常见字幕颜色可能有白色的、黄色的,或者其他颜色,本例电影的字幕是白色。如果是多色字幕,可以按VSF要求取色多色填入。 具体的参数设置,可以参考Docs目录下的readme_eng.txt,专业用户精调参数可以提高Search字幕帧的准确率,从而减少丢时间轴(少字幕图片,致命)和假时间轴(空字幕图片,影响不大)的情况,不过据笔者使用经验,如果没弄明白参数含义和作用,随意调整反而适得其反,普通用户还不如不调的好。 在右边界面先点一下Pixel Color  然后点击字幕白色文字中心骨干取色,点不准可以多点几下。  取到了颜色,会显示出来 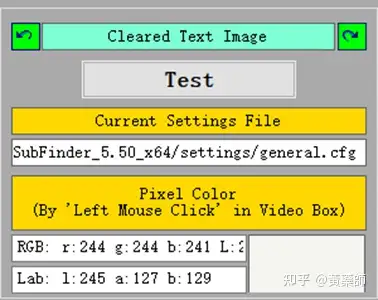 本例将Lab: l:245 a:127 b:129 拷贝后双击填入Use Filter Coloers,一般做了这步就可以基本保证不会有时间轴丢失的情况,算是完成了Search的设置。 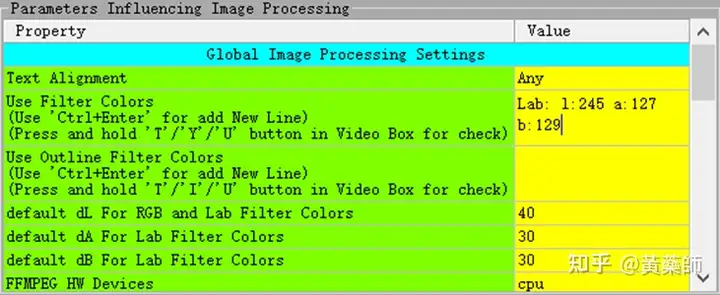 点击Search -> Clear Foders 清空RGBImages目录, 然后点 OCR Search,程序开始扫描视频文件,生成RGBImages。 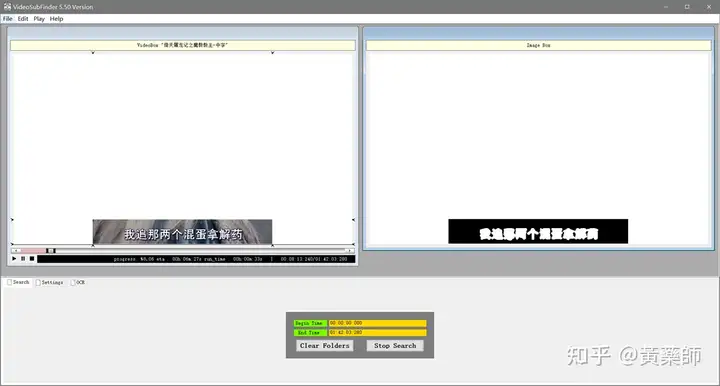 几分钟后扫描完成,可以关掉VideoSubFinder_5.50_x64,这时工具将显示RGBImages目录下的所有字幕截图:  初次使用我们可以在文件列表区按鼠标右键菜单,选‘Open folder’打开RGBImages目录看一下: 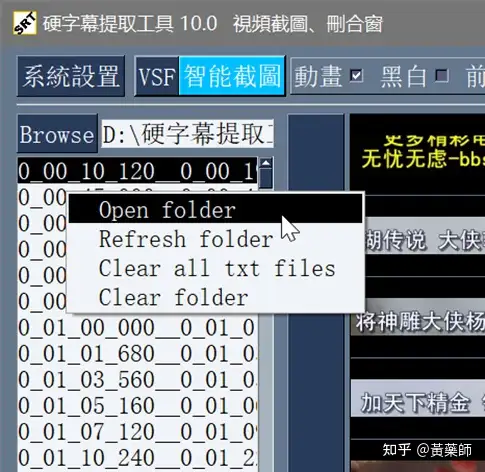 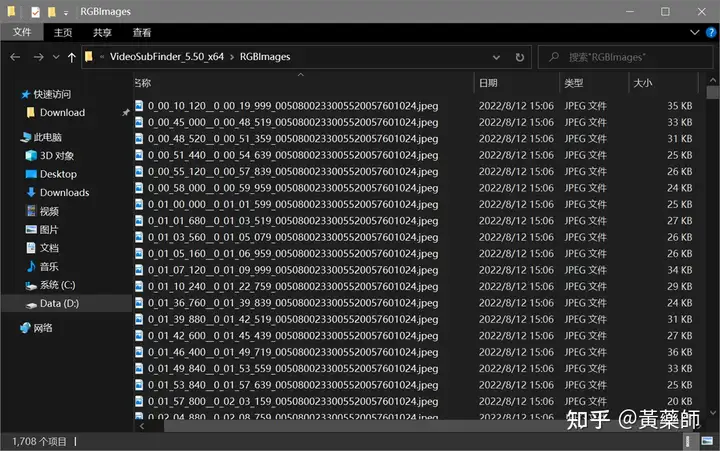 这些是刚才VideoSubFinder_5.50_x64 Search生成的1000多个字幕切片图片文件,说明这个电影有1000多条字幕呢。文件名前段为时间轴信息。 可以打开文件看看,是RGB原色字幕截图切片,很适合AI训练过的OCR引擎做识别。  步骤5、清理空字幕图片 步骤5、清理空字幕图片我们可以在‘删合窗’中清除RGBImages目录中的空字幕图片。 由于VideoSubFinder 的Search算法还没做到100%准确,所以会误生成少量无字幕空图片(假时间轴),有时还会把广告也截图下来,我们在‘删合窗’中用鼠标滚轮快速翻页浏览RGBImages目录,把发现的空字幕、广告水印图片打上删除标记,标记完最后统一删除,让后续百度OCR识别不用浪费每月有限额度,同时在校对阶段不用再频繁做删除工作。 一页可以显示20~300张图片(默认90张),浏览、标记、删除非常方便。 翻页:点击<<<、>>>按键,或键盘PgUp/PgDn键、↑/↓键,或将鼠标指针停留在图片区,滚动鼠标滚轮(强烈建议),可以翻页。 标记:鼠标左键点击可以标记选中图片,再次点击可以去选中。Shift+鼠标左键可以连续多选、连续去选(可跨页)。 删除:直到最后一页标记完成,点<<面板上的‘全删合’按键会弹出删除提示,确认后将删除所有标记过的空图片。 更多方便的功能(例如自动扫描空图、自动合并重复字幕)可以看“用户手册第四节之 高级功能-删合窗(删除合并)” 如下图一处为广告,可以选中标记它: 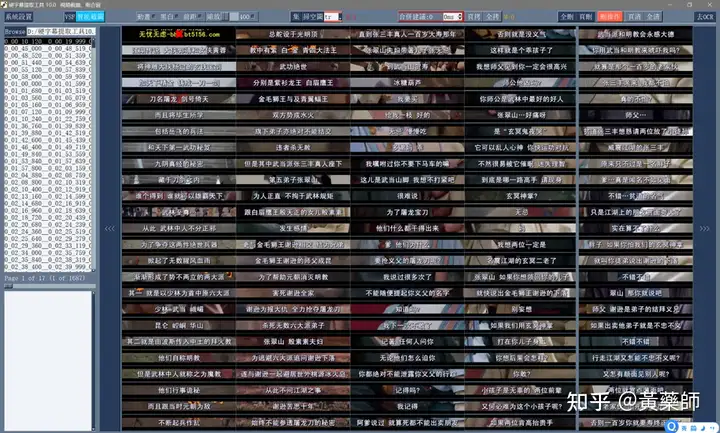 如下图几处为空字幕图片,可以选中标记它: 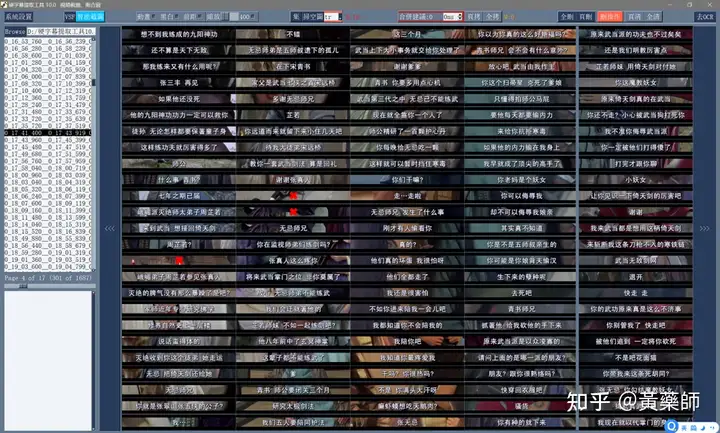 一直标记到最后一页: 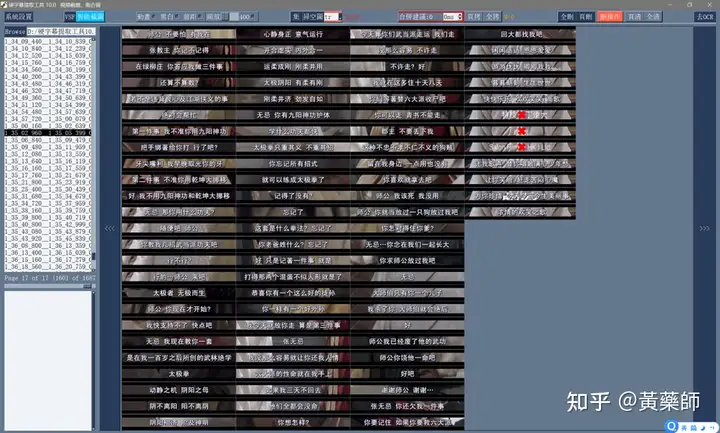 然后点‘全删’,  确认后将会把刚才标记过的所有空字幕、广告水印图片删除掉(如果发现不能删除,多半是系统权限问题,请不要将本工具安装在C盘或桌面): 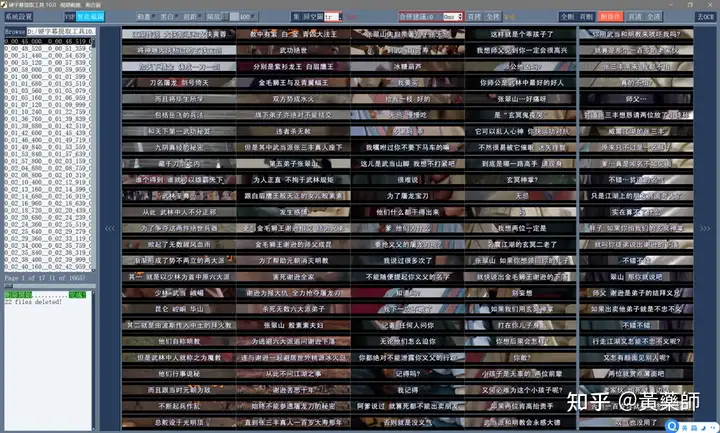 清理完空字幕图片后,点击面板上的‘去OCR’按键,将切换到OCR校对窗。 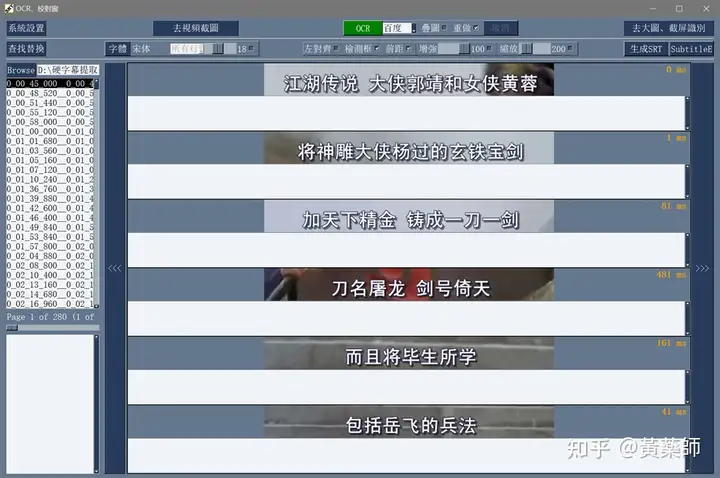 步骤6、运行百度OCR识别 步骤6、运行百度OCR识别百度高精度每月免费识别额度较低,如不采用叠图技术 --- 将多张字幕图片合成一张大图来识别以节省额度,每月只能识别较少字幕图片,因此,如果用户没有购额度,应该在面板上勾选‘叠图’。  如果没有注册百度,而是采用离线识别引擎可选tr并去掉勾选叠图。 点击主界面的OCR按键,程序将连接百度OCR服务器,对RGBImages目录中的所有字幕图片从头到尾按顺序做识别,只需等待完成即可。 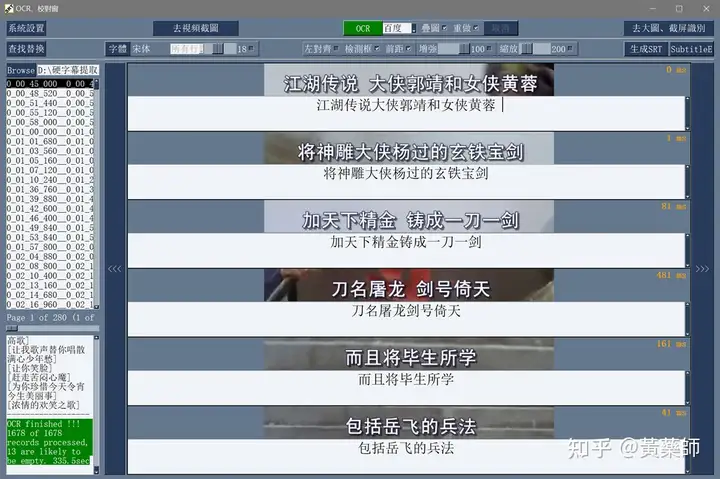 OCR识别完成了! (细心的用户可能会留意到:在识别过程中有少量图片会有自动标注‘X’,这是因为程序在OCR识别过程中会自动标注空字幕图片,因为上个手动删空步骤遗留了少量空字幕图片,所以呢,如果你额度充足,是可以不用做手动删空步骤的) 这时在RGBImages目录下已经为每个.jpeg文件生成了一个同名的 .txt字幕文件,以及检测框坐标文件_boundingbox.txt,初次使用可以看一下。 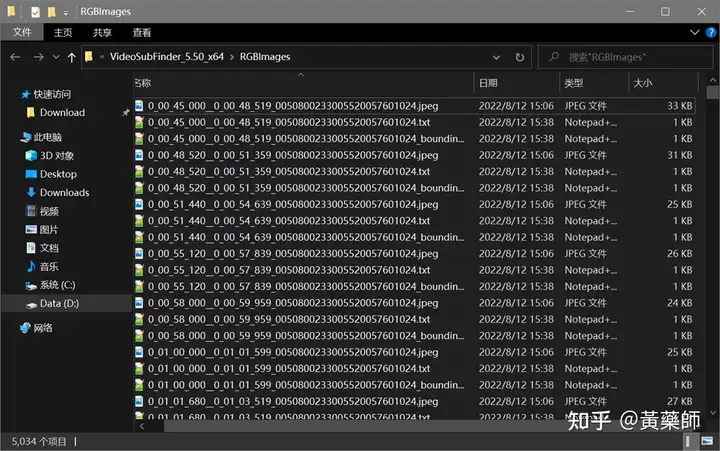 步骤7、校对字幕 步骤7、校对字幕如果希望在SubtitleEdit等字幕软件中做校对,可以略过这个步骤,直接到下个步骤 校对窗显示一页1~4列、1~10行(默认1列6行)图文。用户可根据需要在系统设置里设置。 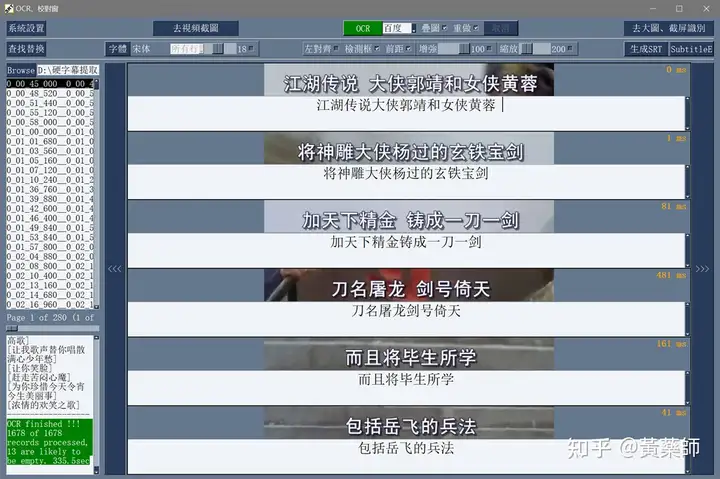 编辑:可以用输入法进行常规的输入、删除、鼠标左键/右键插入空格、回车等操作。 查找替换:除了支持简单的批量替换,还支持* ?通配符、反斜杠转义等扩展找替换、正则表达式匹配替换等。 翻页自动保存:点击<<<、>>>按键,或键盘PgUp/PgDn键,或将鼠标指针停留在图片区,滚动鼠标滚轮、或↑/↓键,都可以进行翻页。翻页将自动保存校对修改过的文字。 选中标记:ctrl+鼠标左键 可以标记删除图片,shift+鼠标左键 可以标记合并图片,再次点击可以去选中。 删除合并:如果有选中的图片,这时按键盘<Delete>按键会弹出删除合并提示,OK确认或<Enter>将执行删除、合并。 删除合并范围:当前页+前1页=2页内,跨页合并是可能的。 校对完成后,按面板上的‘生成SRT’按键,将在RGBImages目录下生成123.srt文件: 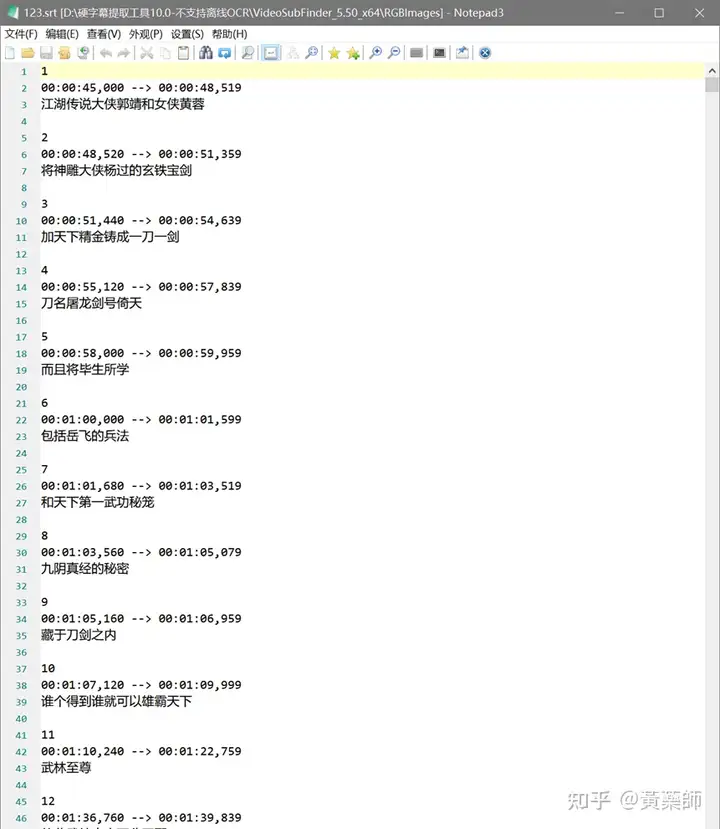 可以大概浏览一下,然后关掉。 生成SRT文件后,如时间轴不需要再调整、字幕不需要比对原视频做补漏(要求不高),则至此字幕提取工作完成。 更多方便的功能(例如‘精准对齐’,‘鼠标左右键自定义功能’,‘字体选择’,‘字号调整’,‘每行字号单独调整’)可以看“第四节之 校对窗” 生成SRT文件后,如需调整时间轴、比对原视频做补漏,点击面板上的‘SubtitleE’按键,将打开SubtitleEdit工具编辑123.srt字幕文件。 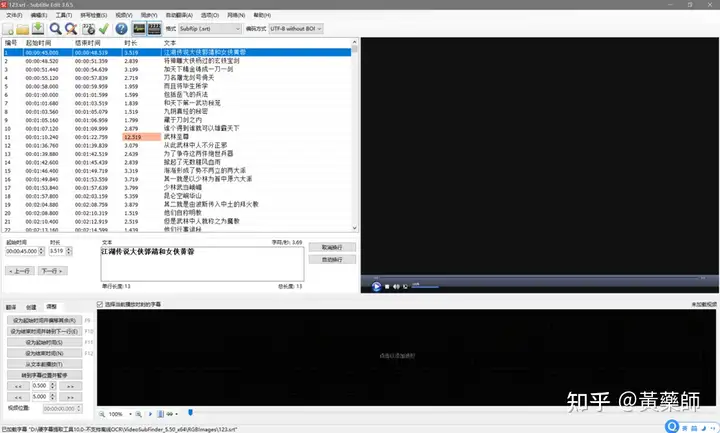 步骤8、用SubtitleEdit编辑字幕文件 步骤8、用SubtitleEdit编辑字幕文件之所以前面在校对窗做过校对,这里又用到APP2来做编辑,是因为有些用户(例如字幕组)对字幕要求高,还需要做调轴、补漏等进一步校对工作。 在波形图窗口里,“点击以添加波形”,打开视频文件,本例是‘倚天屠龙记之魔教教主-中字.mp4’,将生成波形数据:  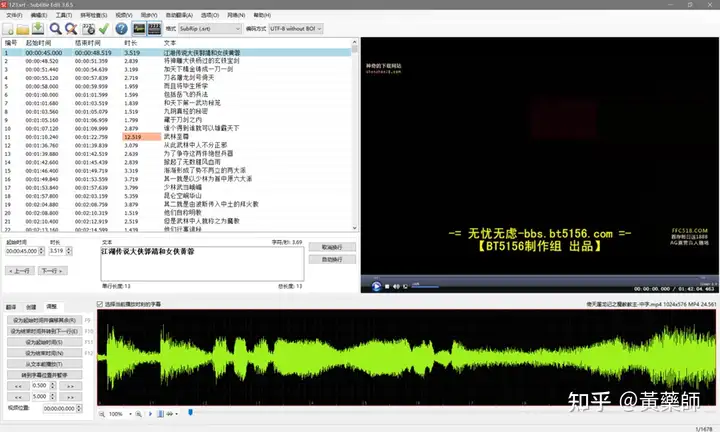 在波形图窗口,勾选‘选择当前播放时刻的字幕’,设定播放速度,例如200%,然后开始播放视频,字幕会同步显示在播放窗口,可随时暂停播放,进行字幕校对、补漏、调轴。 该删除的删除,该修正的修正,该替换的替换,改补漏的补漏、该调轴的调轴,注重细节的用户还是认真过一遍吧。 完成字幕校对后,点击“文件->另存为” 保存校对好的字幕文件,SubtitleEdit会自动将123.srt重命名为跟视频文件同名的srt文件“倚天屠龙记之魔教教主-中字.srt”,并保存在视频文件所在目录下,方便大多数播放软件播放视频文件时自动加载同名字幕文件。 至此,整个硬字幕提取流程就走完了。 问题反馈Q&A: 1、 Q: 软件需要安装吗?运行出错怎么办? A: 绿色免安装,解压即可。如果32bit版本(6.7版及旧版支持32bit、64bit,从7.0版开始将不再更新32bit)运行出现“Failed to execute script pyi_rth_multiprocessing”错误,说明win7x32系统太旧,要先装 KB2533623才行。如果出现找不到dll的报错,请安装Microsoft .NET Framework 4.8和Microsoft Visual C++ 2015-2019。如果运行过程中,执行命令或删除出错,多半是系统权限问题,请不要将VSF及工具软件解压安装在C盘、或者偷懒放到桌面运行,有这种坏习惯要改。 如果是10.0以后版本不能启动,可能是因为没有安装包里的vlc。 2、 Q: APP2指定须要用文档例子中的第三方软件吗? A: 不指定,甚至可以不用设置,本工具将第三方软件集成入工作流中,减少了各个APP来回切换的时间。 3、 Q: 可以自动标注空字幕图片吗,人眼找空字幕费眼神? A:离线版的删合窗有‘扫描空图’功能,可以自动标注‘X’,另外在OCR过程中凡是识别为空的字幕图片,都会自动标记‘X’,不需要用人眼来寻找空字幕. 4、 Q: OCR服务商免费吗? A: 每家OCR服务商提供不同的免费识别额度(每天每月有一定数量,具体看厂家规定),业余人士可利用免费额度。同时厂家经常有优惠活动(例如百度1元购1W次网图,讯飞0元购10W次,有道新注册送100元等)。而对于长期需求用户,建议充点钱购买次数吧,价格不贵,还能支持国家高科技发展。 从7.0版本开始,离线OCR版本提供了tr、paddel、easy离线OCR引擎,不需要任何KEY,可离线使用,完全免费。 5、 Q: 为什么填写了OCR服务商的KEY后,不能识别? A: 请确认开通了服务商的文字识别服务,如识别出现“Network Exception!”错误提示,说明无法连接到OCR厂家的服务器,请检查网络连接是否正常(不要用VPN代理),或重启一下电脑再试。 6、 Q: 高精度和低精度识别率差别大吗? A: 对于清晰简单的字幕,差别不大,模糊复杂(多种语言混合)的字幕、大图识别,差别较大,在批量识别前可做识别试验,以便选择最佳设置。 7、 Q: 有时候叠图出现‘间隔标记丢失,尝试纠正!’的告警提示,怎么办? A: OCR厂商训练的机器学习模型,对不同特征的图片识别能力不同,甚至有些特殊爱好或怪癖,例如百度OCR对于模糊字幕的叠图容易丢失间隔标记(模糊与清晰并存时眼睛有点花),其他厂家的OCR则没有这种问题。有些语言类型设置会丢失第一个英文字符,有些会丢失标点,小问题不一而足。每种机器学习模型的情况都不同,在批量识别前可先做识别试验(包括加入增强魔棒),以便获得最佳设置,得到最佳识别结果。 8、 Q: 极速叠图会导致识别率降低吗? A: 对于清晰简单的字幕,识别率只有轻微降低,几乎没有影响。模糊复杂(多种语言混合)的字幕,降低较明显,如果出现识别率明显降低,或者出现‘间隔行丢失,尝试纠正... 如经常出现,请改用半叠或不叠’的告警提示,可中止识别,改为半叠或者不用叠图。叠图的主要好处是节省额度、节省时间。 9、 Q: 想快速切换浏览图片,怎样操作最快速、方便? A: 请用鼠标滚轮来做图片切换浏览,滚动时请将鼠标指针停留在图片区中,然后滚动滚轮,养成使用习惯后会很方便。 10、 Q: 批量识别过程中出现Network Exception错误、额度用完、手动中止,导致识别未完成,又不想重头识别,想从中断点处继续识别怎么操作? A: 主界面‘重做’去勾选,接下来再做批量识别将自动从中断点处继续识别。 11、 Q: 识别率不高、漏字、错字、漏标点、漏空格,怎么办? A: 识别率主要由OCR厂家训练的机器学习模型决定,遇到识别率问题,可以: 1) VSF、智能截图的截图框尽量接近字幕文字,让图片中的文字尽量显大 2) 更换OCR厂家 3) 更改语言类型设置 4) 利用‘增强魔棒’提高识别率 5) 如果用了叠图,可以改为半叠或者不叠 6) 识别完成后,利用校对窗、SubtitleEdi、Aegisub等字幕软件替换错误字符 12、 Q: 百度高精度识别率挺高的,多数情况下只需要补上识别丢失的空格,就能完成文字校对工作了。有办法提高插入空格速度吗? A: 7.0版开始支持“鼠标左键或右键一键插入空格”只需要按一下鼠标就能插入一个空格,补漏空格变得更轻松了。 13、 Q: OCR批量识别完成后,是在校对窗中校对,还是在APP2第三方字幕软件中校对? A: 看个人喜爱,校对窗提供了精准对齐功能,可以大大提高校对速度。 14、 Q: 网页截图识别没反应?如何提高网页、pdf文件截图识别率? A: 需要先安装第三方截图软件如Snipaste或QQ截图,然后配合本工具才能实现截图识别。为了提高识别率,可以选用高识别率OCR厂家、还可开启增强魔棒,推荐使用Snipaste截图软件并将输出图像质量设置成100。 15、 Q: 想用离线OCR识别? A: 7.0版本开始内置支持离线OCR(须安装支持离线OCR的版本,体积较大)。也可以用ABBYY,文末VSF + SubtitleEdit (64bit)下载,内有VSF中文使用手册,有个简单步骤可以参考。 16、 Q: 检测框有什么作用? A: OCR通常包含两个步骤‘检测’+‘识别’,也就是先用检测算法扫描图片,确定哪些位置有文字以做后续识别,这些位置是用检测框的长方形坐标表示的,因此很容易通过显示检测框来判断检测算法是否可靠,例如是否框对了位置?是否漏框了?只要OCR服务返回的数据中包含坐标信息,都可以显示检测框,支持随时开启和关闭显示。 17、 Q: 能支持sup、idx+sub图片字幕吗? A: 用户给出了简单的方法:把sup或idx+sub丟進SubtitleEdit,在OCR文字區按右鍵>匯出,選擇最後一項的「圖像名稱以時間碼儲存」,選擇輸出(dumy.png)到文件夾,硬字幕提取工具就能以正常時間碼生成SRT。同时喜欢用 esrXP生成idx+sub的用户也可以试试这种方法,具体可参考手册第四节之 SUP/IDX+SUB 图形字幕OCR。 18、 Q: 智能截图速度能再快些吗? A: 将持续优化。如对时间轴精度要求不太高,可以将智能截图间隔由100ms改为200ms,可提速一倍。 19、 Q: 使用时遇到报毒?担心程序植入了木马? A: 请不用担心,因为本工具是python打包,很多防毒软件会误报(除非购买白名单证书或申请鉴定)。如不信,你可以不用,如果要抬杠,可以找人破解本工具代码,给出真实证据。 20、 Q: 智能截图,有时候出来图片重复很多,手动合并很费劲? A: 框字幕的时候请预留一些空间给检测模型,不要框得太紧了,预留1/8~1/4字符高度空间。
|  |Archiver|手机版|deepfacelab中文网
|网站地图
|Archiver|手机版|deepfacelab中文网
|网站地图






 楼主
楼主 发表于 2022-12-24 12:19:04
发表于 2022-12-24 12:19:04

