|
|
【声明】本人只提供基于Stable Diffusion(sd)的AI绘画相关教程,三次元模型生成相关图片的责任都将由使用者本人承担。






上面是跑出来的宋轶lora模型,根据tags生成。
1.lora模型训练素材准备,1-1000张高清正面照片,大头照也可以,材标准,正面图,脸部不能有遮挡,脸不能背景不能复杂,图要高清,起码2mb ,小于的我都删了。经过图像处理后的图片能包含完整的人物(full boddy),或者完整的脸(detailed face),如果裁剪后的图片只有半边身体或者半张脸,那么后续模型的使用中也很容易出现生成的人物跑出图片或被奇怪的东西挡住情况。大概要上面生成的这张图一样。
2.裁剪,可以用本地也可以用网站等,尺寸推荐512x768,裁剪后的图片一定要复查,没有脸的,斜的都不能要,要精不能粗制滥造。
3.图片放本地或者云sd跑就行,这些教程网上很多就不说了
4.训练用的模型一点要这个
sd1.5 三次元一般用这个
https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.safetensors 7gb的
或者Chilloutmix-Ni 7gb 这个效果还没有实验
5.训练参数
# LoRA train script by @Akegarasu
# Train data path | 设置训练用模型、图片
pretrained_model="./sd-models/model.safetensors" # base model path | 底模路径
train_data_dir="./train/aki" # train dataset path | 训练数据集路径
# Train related params | 训练相关参数
resolution="512,768" # image resolution w,h. 图片分辨率,宽,高。支持非正方形,但必须是 64 倍数。
batch_size=2 # batch size
max_train_epoches=20 # max train epoches | 最大训练 epoch
save_every_n_epochs=2 # save every n epochs | 每 N 个 epoch 保存一次
network_dim=128 # network dim | 常用 4~128,不是越大越好
network_alpha=64 # network alpha | 常用与 network_dim 相同的值或者采用较小的值,如 network_dim的一半 防止下溢。默认值为 1,使用较小的 alpha 需要提升学习率。
clip_skip=2 # clip skip | 玄学 一般用 2
train_unet_only=0 # train U-Net only | 仅训练 U-Net,开启这个会牺牲效果大幅减少显存使用。6G显存可以开启
train_text_encoder_only=0 # train Text Encoder only | 仅训练 文本编码器
128和64可以换成32.32都可以,128生成144大小的lora模型。64生成70mb模型
6.开始训练,生成的safetensors文件找一个loss最低的使用
total optimization steps / 学習ステップ数: 19400steps: 0% 0/19400 [00:00<?, ?it/s]epoch 1/20steps: 0% 42/19400 [00:41<5:16:43, 1.02it/s, loss=0.114]
上面显示第一个loss0.114
看剩下的几个,选最小的就行
7.模型使用
把lora模型放到具体位置,不推荐任何云sd,云sd感觉lora都是坏的,最好用本地的
主模型用sd1.5(人脸符合原图) 7gb或者4gb都可以,电脑好用7gb,不行选4gb
也可以用Chilloutmix-Ni作为主模型(生成的人脸想韩国人)
https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.safetensors
具体位置看图



8.tags
best quality, black long hair, ultra high res, (photorealistic:1.4), 1girl,silver dress,(azur lane\), nsfw, nude,(Kpop idol), (aegyo sal:1), (light brown short ponytail:0.8), ((puffy eyes)),,hanfugirl,light green hanfu, floral print,
可以去civitai找符合模型人脸的tags,复制套用就可以,多试几次就可以,具体内容就是描述中文翻译
也可以去专门的tags网站自动生成tags,但是效果都不好,很费时间,个人建议c站上复制别人好看图的tags,然后微调
9.总结
训练素材的照片应该是越多越好,生成的图片才会丰富,当然几十张高质量图片也行
理论上只要有人物的高清正面照片,1-3个小时就可以合成自己想看的任何ai照片,自己欣赏即可,请勿传播。
|
-

|
 |Archiver|手机版|deepfacelab中文网
|网站地图
|Archiver|手机版|deepfacelab中文网
|网站地图



 楼主
楼主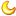

 发表于 2023-2-23 14:08:39
发表于 2023-2-23 14:08:39