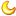|
|
星级打分
平均分:NAN 参与人数:0 我的评分:未评
本帖最后由 windjet 于 2023-6-18 19:19 编辑
这是CelebA数据集的属性选择器(SAFC)的V1版,带一个高质量150万预训练模型,模型为WF256分辨率,Dfud结构,同时附送4万头像数据集,利用它你可以随意定制自己的训练集,如正在训练眼镜妹子,那么就定制一份带眼镜的女性头像集合就行了,这利用SAFC可以在几分钟内内就能轻易做到这一点,不需要部署任何环境,具体请看附带的使用说明。
CelebA数据集是正规研究机构香港中文大学多媒体实验室发布的一个强大的数据集合,完全不同于那些个人在网上爬取的头像集合,个人整理的头像集合只能称之为图片包,不能称为数据集合,所谓数据是经过整理归类并能再利用的逻辑归纳,这才是CelebA数据集的强大之处。
CelebA数据集带有多种特性,这里只说一下它和DeepFaceLab相关的特性,就是它有丰富的描绘人脸特征的40个属性,包括性别,发色,刘海,眼镜,可爱,年轻,胡须等各个人脸特征,利用这些属性特征可以轻易的定制一份自己需要的训练集合,如戴眼镜的年轻又可爱的女性等。
但不会编程的人无法提取CelebA数据集的属性特征,也就无法利用CelebA的强大之处,所以就做了这个属性选择器,来帮助大家更加方便的使用CelebA数据集,也能体验到这个数据集的便利和强大。
另外值得特别说明的是,DeepFaceLab的开发者也是使用CelebA数据集来做测试的,你可以看一看20211120原版DFL的\_internal\DeepFaceLab\test.py文件就知道了,里面含有大量CelebA信息,比如8293行,它是默认指定CelebA数据集(pretrain_CelebA)来预训练的,就不用说例子里面的\_internal\DeepFaceLab\samplelib\SampleGeneratorFaceCelebAMaskHQ.py文件了,基本上就是利用了CelebA蒙板高清衍生数据集(CelebAMask-HQ)来操作演示,这大概是因为目前的通用大型数据集里面只有CelebA数据集是属性最多,角度可能也是最全的。
其实灵感也来源于滚石大佬的GPT4初体验一个帖子,当时大佬问GPT4能否找到一些没有刘海的美女图片集来训练AI,GPT4回答说可以利用CelebA数据集,可能没有特定的“无刘海”标签,但可以根据其它属性来筛选出所需要的图片,这让我很吃惊,因为我知道CelebA数据集的确没有“无刘海”属性,但它有“有刘海”属性啊,利用它的反义就能轻易筛选出没有刘海的女性图片,如果这是GPT4没有接受过CelebA数据集的文本属性内容就自己推断出的这个回答,那就真的太牛了!总之,通过这我就有了开发一个CelebA数据集的属性选择器的想法,来方便大家更好的利用CelebA的特性。
CelebA的40个属性列表:
1:浅胡须,2:柳叶眉,3:可爱的,4:眼袋,5:秃头,6:有刘海,7:大嘴巴,8:大鼻子,9:黑发,10:金发
11:模糊的,12:棕发,13:浓眉,14:胖的,15:双下巴,16:戴眼镜,17:山羊胡,18:灰发,19:浓妆,20:高颧骨
21:男性,22:微张嘴,23:有胡子,24:小眼睛 ,25:没胡须,26:椭圆脸,27:白皮肤,28:尖鼻子,29:发际线后移
30:双颊红润,31:络腮胡,32:微笑,33:直发,34:卷发,35:带耳环,36:戴帽子,37:涂口红,38:带项链,39:带围巾,40:年轻的
------------------------
下面是附带的1000个样本头像的运行结果图,选择的正向属性是[10:金发],反向属性是[6:有刘海和[21:男性],输出是金发没有刘海的女性。
CelebA属性选择器(SAFC)运行图
运行图")
模型为标准官方预训练模型,主要是利用CelebA数据集训练的,用它做底丹可以快速建立起各种专有模型,CelebA训练效果如下:
CelebA数据集训练图

当然该模型(底丹)也训练了官方素材,中国明星,网红及日本老师等。
中国明星:
中国明星训练图

中国网红:
中国网红训练图

日本老师的图就免了。
在这次的CelebA属性选择器(SAFC)里面,还有免费送的CelebA的WF512头像1万张和WF256头像3万张,小规模的训练是够用了的,如果你要求大规模训练需要完全版,请下载下面已经发布的CelebA数据集合,最大的完全版有20张万头像:
WF512版,11万5千张:
https://dfldata.cc/forum.php?mod=viewthread&tid=13775
香港中文大学CelebA预训练集-WF512版-量大角度全-11万5千张
WF256版,20万张:
https://dfldata.cc/forum.php?mod=viewthread&tid=13537
香港中文大学CelebA预训练集-20万头像-论坛数量最多角度最全
WF1024版,即CelebA蒙板高清衍生数据集CelebAMask-HQ(已经整合到WF512版里面):
这是以前的“香港中文大学CelebA衍生预训练集-3万头像-官方高清WF512”的帖子的改版,已经转为1024分辨率的升级版并额外增加了纯女性WF1024版,不再单独提供下载,经版主建议,已经重新切成分辨率1024的WF1024头像并整合到上面的WF512版里面。
附带模型为官方标准预训练模型,也就是它必须关闭预训练模式才能正式使用,当然你也可以拿它继续进行预训练。
如果你要马上使用该模型来训练万能丹,可以参考以下方法:
1,把该模型所有文件都拷贝到\workspace\model下面,src和dst的aligned文件夹当然也得放入相应的头像文件,比如\data_src\aligned里放目标头像,\data_dst\aligned里面放CelebA训练集的faceset.pak包。
2,运行6) train SAEHD.bat开启训练,选择该模型和要训练的设备之后,等待片刻,会提示2秒钟内按enter回车以修改模型设置,在规定的时间内按它进入参数设置环节。
3,在最后一个选项时(是否启用预训练模式 Enable pretraining mode)输入n,以此来关闭预训练模式。
[n] Enable pretraining mode ( y/n ?:help ) :n
4,等待训练预览图出来后,应该是只有单列的左边能出清晰头像的,迭代次数应该是从0重新开始的,这时点右上角的叉直接关闭预览图和运行的两个窗口,不用特意保存模型,第1次运行只要出来了预览图就说明已经自动保存好了。
5,把原始预训练模型文件夹中几个.npy文件(注意只拷贝.npy格式的文件,其余文件不要拷贝)复制到训练中的模型文件夹中覆盖当前文件,千万不要拷贝.dat文件,不然又白忙了。
6,再次运行6) train SAEHD.bat,一切按默认的回车即可,最后的选项由于自动保存过,所以应该已经是关闭预训练模式了的。
7,再次出现预览图时,应该是两列都比较清晰的头像,点击预览图窗口后按P键可以变换预览图,如果你没有看到较清晰的预览图,估计是你哪个环节弄错了,请仔细确认各个环节然后从1开始再来一遍。
更新日志:
---2023年05月30日
1,使用4万真人大角度图片对预训练模型进行了角度特训,使其迭代次数达到150万,改善了正训时角度训练慢的问题,建议已经购买过链接的再重新下载最新版本的预训练模型。
---2023年04月18日
1,增加了一个利用CelebA数据集训练的高质量122万预训练模型,模型为WF256分辨率,Dfud结构,已经购买过链接的可以免费获取。
|
评分
-
查看全部评分
|
 [复制链接]
[复制链接]
 |Archiver|手机版|deepfacelab中文网
|网站地图
|Archiver|手机版|deepfacelab中文网
|网站地图





 楼主
楼主

 发表于 2023-10-15 19:06:13
发表于 2023-10-15 19:06:13